This story starts with a Product Catalog database, stored in a bucket called MyBucket. MyBucket stores 18000 documents for a total storage of 39MB. The bucket is small but since data have been completely normalised, queries use joins a lot. In MyBucket, documents can be produit, categorie, or have other document types:
- produit is a commercial product
- categorie is a commercial category
A product is designed as depicted in the following picture :

A product is embedding an array called categories. This array categories is a list of anonymous documents, each having a single field called identifiantCategorie. A field identifiantCategorie stores a foreign key to a category document, designed as follow :

The original query is doing a join between a product and a given category, to find all products having a given category in its array categories. For instance, here is the query to find all products referring to category_1 :

Step 0: explain the query
First, let's EXPLAIN the query :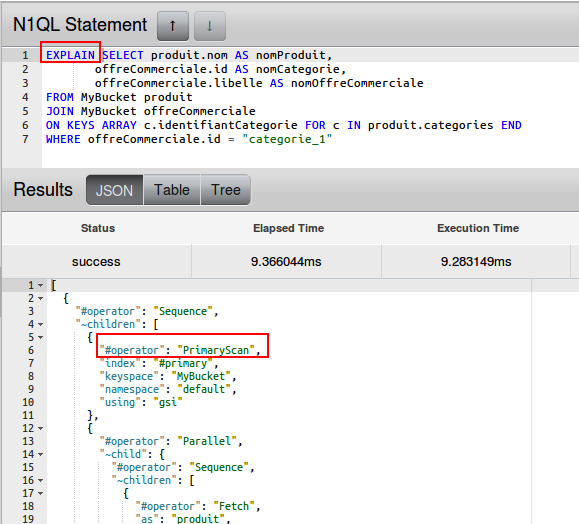
As we can see, this query is doing a full scan using the primary index on this bucket. This means that for each document in MyBucket, Couchbase needs to retrieve each document in order to test for the presence of an array called categories, and perform the join. Depending on the size of the bucket, the response time can grow.
Step 1: modify the document design
Let's add a property type in each document that will reflect the document type and define virtual collections in the same bucket:
- product document : adding "type":"produitCommercial"
- category document : adding "type":"categorie"
We now update the query to filter documents based on their type.

Then we create an index on this new field to accelerate the fetch of documents.
Don't forget to check that the new index will be used by the query:

Finally test the query :

The query execution time is now 356 ms, so more than 7 times faster than before ! This improvement is due to the selectivity of this new field. A quick count on MyBucket to find all documents where type="produitCommercial" shows that there are 2005 products, so a selectivity of (2005/18000)=11%.
Since there are several document types in the same bucket, create a index on this field will split the bucket into different virtual collections and speed up the fetching of each collection. Of course with a single document type in the bucket, these kind of optimisation will never improve response time since all documents will have the same type value (and a selectivity of 100%).
Step 2 : Memory-Optimized Global Indexing with Couchbase 4.5
Now let's backup and restore the data from this Couchbase 4.1 node to a Couchbase 4.5 node. Couchbase 4.5 is actually in Developper Preview and will be released soon. Couchbase 4.5 will provide a bunch of new features and faster indexing. To make the best of new Couchbase 4.5 indexing, Memory-Optimised Global Indexing has been activated in this node.
Memory-optimized global indexes enable in-memory index processing and index scans with the lowest latency. These indexes will be stored in RAM only, rather than part in memory, part in disk as they are in Couchbase 4.1.
With exactly the same configuration as before, the query is already much faster when running with Memory-Optimised global index, now executed in 222ms instead of 356ms :

Step 3 : Array indexing
Looking deeper in the execution plan, we notice that the join operation is looping on every identifiantCategorie field of each document inside the categories array of a product.
What is we could index this identifiantCategorie field ? Since Couchbase 4.5, array indexing has been added. This means that the content of an array can be indexed, not only the whole array itself (already available in Couchbase 4.1). Let's create an index on the identifiantCategorie field of each document inside the categories array of a product.
Is this index used by the query ? In a matter of fact no. The query need to be customised in order to make it use the new index :

Surprisingly, the new response time is worse than before : 293 ms instead of 222 ms. What happened ? Both indexes are queried and intersected. The use of both indexes make the query slower. Fortunately, we can force N1QL to use the index we want, with the USE INDEX clause.

The query is now executed in 24.74 ms ! Much better. In fact, more than 100 times faster than the initial query.
Step 4 : Covering index
Explaining the query shows that data are fetched from the data service.

To eliminate this step, we create a covering index : when an index includes all the actual values of all the fields specified in the query, the index does not require an additional step to fetch the values from the data service.
We want N1QL to use this new index and we check how this index is explained:

There is no more fetch step in the query execution plan because every information needed by the query is already stored within the index, and in memory thanks to Memory Optimised Global Index.
The new query response time is now less than 6ms, more than 430 times faster than the initial query !

Conclusion
We've seen a number of ways to improve a N1QL query response time:
- Use a specific type field to create virtual collections and create an index on this field. The more selective is the field the more efficient will be the index.
- Use Memory-Optimised Global Index, available with Couchbase 4.5
- Add array indexing if your query references to a field inside an embedded array
- USE INDEX can be used to force the use of a preferred index inside a N1QL query
- To get the best response time, try and create a covering index to avoid the fetch step
- EXPLAIN, EXPLAIN and EXPLAIN again !